Overview #
This folder holds the Topology-aware scheduler plugin implementations based on Topology aware scheduler plugin based on NodeResourceTopology CRD. This plugin enables scheduling decisions based on worker node hardware topology overcoming the issue described here.
Document capturing the NodeResourceTopology API Custom Resource Definition Standard can be found here.
Maturity Level #
- 💡 Sample (for demonstrating and inspiring purpose)
- 👶 Alpha (used in companies for pilot projects)
- 👦 Beta (used in companies and developed actively)
- 👨 Stable (used in companies for production workloads)
Tutorial #
Expectation #
In case the cumulative count of node resource allocatable appear to be the same for both the nodes in the cluster, topology aware scheduler plugin uses the CRD instance corresponding to the nodes to obtain the resource topology information to make a topology-aware scheduling decision.
NOTE:
- NodeResourceTopology version v0.0.12 onwards, CRD has been changed from namespace to cluster scoped. Scheduler plugin version > v0.21.6 depends on NodeResourceTopology CRD v0.0.12 or newer and the namespace field has been deprecated from the NodeResourceTopology scheduler config args.
Compatibility Matrix #
NodeResourceTopologyMatch plugin to work properly requires specific version of NodeResourceTopology CRD:
| Scheduler Plugins | NodeResourceTopology CRD version |
|---|---|
| master | v0.1.0 |
| v0.24.9 | v0.0.12 |
| v0.23.10 | v0.0.12 |
| v0.22.6 | v0.0.12 |
| v0.21.6 | v0.0.10 |
| v0.20.10 | v0.0.10 |
| v0.19.9 | v0.0.10 |
In case NodeResourceTopology CRD is being installed and advertised by NFD, check compatibility matrix below:
| Scheduler Plugins | NodeResourceTopology CRD version | NFD version |
|---|---|---|
| master | v0.1.0 | master |
| v0.24.9 | v0.0.12 | > v0.10.0 |
| v0.23.10 | v0.0.12 | > v0.10.0 |
| v0.22.6 | v0.0.12 | > v0.10.0 |
| v0.21.6 | v0.0.10 | N/A |
| v0.20.10 | v0.0.10 | N/A |
| v0.19.9 | v0.0.10 | N/A |
Config #
Scheduler #
Enable the “NodeResourceTopologyMatch” Filter and Score plugins via SchedulerConfigConfiguration.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: topo-aware-scheduler
plugins:
multiPoint:
enabled:
- name: NodeResourceTopologyMatch
reserve:
disabled:
- name: NodeResourceTopologyMatch
# optional plugin configs
pluginConfig:
- name: NodeResourceTopologyMatch
args:
# other strategies are MostAllocated and BalancedAllocation
scoringStrategy:
type: "LeastAllocated"
Scheduler-side cache with the reserve plugin #
The quality of the scheduling decisions of the “NodeResourceTopologyMatch” filter and score plugins depends on the freshness of the resource allocation data. When deployed on large clusters, or when facing high pod churn, or both, it’s often impractical or impossible to have frequent enough updates, and the scheduler plugins may run with stale data, leading to suboptimal scheduling decisions. Using the Reserve plugin, the “NodeResourceTopologyMatch” Filter and Score can use a pessimistic overreserving cache which prevents these suboptimal decisions at the cost of leaving pods pending longer. This cache is described in detail in the docs/ directory.
To enable the cache, you need to both enable the Reserve plugin and to set the cacheResyncPeriodSeconds config options. Values less than 5 seconds are not recommended
for performance reasons.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: topo-aware-scheduler
plugins:
multiPoint:
enabled:
- name: NodeResourceTopologyMatch
# optional plugin configs
pluginConfig:
- name: NodeResourceTopologyMatch
args:
# other strategies are MostAllocated and BalancedAllocation
scoringStrategy:
type: "LeastAllocated"
cacheResyncPeriodSeconds: 5
ScoringStrategy #
The topology-aware scheduler supports four scoring strategies. You can set a strategy via SchedulerConfigConfiguration, by setting the scoringStrategy option. There are four supported strategies:
- MostAllocated
- BalancedAllocation
- LeastAllocated
- LeastNUMANodes
The MostAllocated, BalancedAllocation and LeastAllocated strategies only work with the single-numa-node Topology Manager policy and indicate how score of the worker node will be calculated based on current utilization:
- MostAllocated - favors node with the least amount of available resources
- BalancedAllocation - favors node with balanced resource usage rate
- LeastAllocated - favors node with the most amount of available resource
The LeastNUMANodes strategy works with all the Topology Manager policies and favors nodes which require the least amount of topology zones to satisfy the resource requests for a given pod.
Cluster #
The Topology-aware scheduler performs its decision over a number of node-specific hardware details or configuration settings which have node granularity (not at cluster granularity). Consistent settings across a set of nodes or all over the cluster is a fundamental prerequisite for the scheduler to work correctly. In other words, it is a prerequisite that a set of nodes share the same NUMA topology and kubelet configuration, at least for settings like topology and resource (cpu, memory, device) managers.
However, the scheduler has no means to enforce or even validate this prerequisite; for example the NodeResourceTopology CRD does not expose all the relevant fields, nor it should (it would be out of scope).
Hence, proper cluster configuration is expected from the cluster admins, or to other software components, like controllers or operators, outside the scope here.
Should the cluster need to have different settings (e.g. topology manager) or NUMA topologies, we recommend to use the standard kubernetes tools to identify each set of nodes using affinity or also taints.
Topology Manager configuration #
Target audience: developers and operators of topology updaters (NodeResourceTopology producers)
In addition to logically partitioning a cluster like explained above, the topology-aware scheduler needs to know key node-specific configuration settings like Topology manager policy and scope.
This data is expected to be provided as top-level Attributes of the NodeResourceTopology objects:
NodeResourceTopology producers should add top-level Attributes in the following format
- For
NameandValueof attributes, words should besnakeCase - The
Nameof each attribute should be the same of the corresponding kubelet configuration option.- example:
--topology-manager-scopebecomestopologyManagerScope - example:
topologyManagerPolicybecomestopologyManagerPolicy
- example:
- The
Valueof each attribute should be one of the value of the corresponding kubelet configuration option, VERBATIM.- example:
single-numa-nodebecomessingle-numa-node
- example:
- Should
topologyManagerOptionsbe exposed:- they should be expanded in key-value pairs, using the
String()representation - each key-value pair should be preceded by the
topologyManagerOptionprefix - every other provision described above applies
- example: the
prefer-closest-numa-nodesoption becomestopologyManagerOptionPreferClosestNumaNodes, accepting exactly one of eithertrueandfalse. - RATIONALE: this representation wants to guarantee all the Attribute Names are unique (no aliasing). It must be noted this is a stricter requirement with respect to the Attribute representation in NRT objects, and this requirement could be lifted in the future (an upgrade path will be provided).
- they should be expanded in key-value pairs, using the
Demo #
Let us assume we have two nodes in a cluster deployed with sample-device-plugin with the hardware topology described by the diagram below:
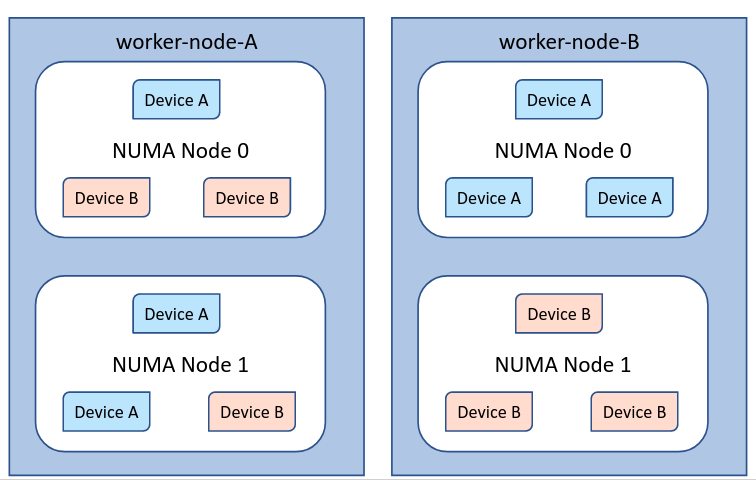
The hardware topology corresponding to both the nodes is represented by the below CRD instances. These CRD instances are supposed to be created by Node Agents like Resource Topology Exporter (RTE) or Node feature Discovery (NFD). Please refer to issue Exposing Hardware Topology through CRDs in NFD and Design document which captures details of enhancing NFD to expose node resource topology through CRDs.
For configuring your cluster with NFD-topology updater, a software component in Node Feature Discovery which creates NodeResourceTopology CRs corresponding to nodes in the cluster follow the Quick Start guide here.
# Worker Node A CRD spec
apiVersion: topology.node.k8s.io/v1alpha2
kind: NodeResourceTopology
metadata:
name: worker-node-A
topologyPolicies: ["SingleNUMANodeContainerLevel"]
zones:
- name: numa-node-0
type: Node
resources:
- name: cpu
capacity: 4
allocatable: 3
available: 3
- name: example.com/deviceA
capacity: 1
allocatable: 1
available: 1
- name: example.com/deviceB
capacity: 2
allocatable: 2
available: 2
- name: numa-node-1
type: Node
resources:
- name: cpu
capacity: 4
allocatable: 3
available: 3
- name: example.com/deviceA
capacity: 2
allocatable: 2
available: 2
- name: example.com/deviceB
capacity: 1
allocatable: 1
available: 1
# Worker Node B CRD spec
apiVersion: topology.node.k8s.io/v1alpha2
kind: NodeResourceTopology
metadata:
name: worker-node-B
topologyPolicies: ["SingleNUMANodeContainerLevel"]
zones:
- name: numa-node-0
type: Node
resources:
- name: cpu
capacity: 4
allocatable: 3
available: 3
- name: example.com/deviceA
capacity: 3
allocatable: 3
available: 3
- name: numa-node-1
type: Node
resources:
- name: cpu
capacity: 4
allocatable: 3
available: 3
- name: example.com/deviceB
capacity: 3
allocatable: 3
available: 3
-
Verify if the CRD has been created by running
-
In case NFD/RTE is deployed in the cluster ensure that the CRD and CRD instances are created by running
$ kubectl get noderesourcetopologies.topology.node.k8s.io -
Alternatively, in case you are just interested in simply testing the scheduler plugin, use the manifest in the manifest directory to deploy the CRD and CRs as follows:
-
Deploy the Custom Resource Definition manifest
$ kubectl create -f crd.yaml -
Check if the noderesourcetopologies.topology.node.k8s.io CRD is created
$ kubectl get crd $ kubectl get noderesourcetopologies.topology.node.k8s.io -
Deploy the CRs representative of the hardware topology of the worker-node-A and worker-node-B if CRs haven’t been created using RTE or NFD as mentioned above:
$ kubectl create -f worker-node-A.yaml $ kubectl create -f worker-node-B.yamlNOTE: In case you are testing this demo by creating CRs manually, ensure that the names of the nodes in the cluster match the CR names.
-
-
-
Copy cluster kubeconfig file to /etc/kubernetes/scheduler.conf
-
Build the image locally
$ make local-image -
Push the built image to the image registry:
$ docker push <IMAGE_REGISTRY>/scheduler-plugins/kube-scheduler:latest -
Deploy the topology-aware scheduler plugin config
$ kubectl create -f scheduler-configmap.yaml -
Deploy the Scheduler plugin
$ kubectl create -f cluster-role.yaml serviceaccount/topo-aware-scheduler created clusterrole.rbac.authorization.k8s.io/noderesourcetoplogy-handler created clusterrolebinding.rbac.authorization.k8s.io/topo-aware-scheduler-as-kube-scheduler created clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-volume-scheduler created rolebinding.rbac.authorization.k8s.io/topo-aware-scheduler-as-kube-scheduler created clusterrolebinding.rbac.authorization.k8s.io/noderesourcetoplogy created $ kubectl create -f deploy.yaml deployment.apps/topo-aware-scheduler created -
Check if the scheduler plugin is deployed correctly by running the following
$ kubectl get pods -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINES topo-aware-scheduler-764c475854-vpmcw 1/1 Running 0 2s 10.244.0.14 kind-control-plane <none> <none> -
Deploy the pod to be scheduled with topology-aware scheduler plugin by populating the schedulerName: topo-aware-scheduler
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
spec:
selector:
matchLabels:
name: test
template:
metadata:
labels:
name: test
spec:
schedulerName: topo-aware-scheduler
containers:
- name: test-deployment-1-container-1
image: quay.io/fromani/numalign
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c"]
args: [ "while true; do numalign; sleep 100000; done;" ]
resources:
limits:
cpu: 1
memory: 100Mi
example.com/deviceA: 1
example.com/deviceB: 1
requests:
cpu: 1
memory: 100Mi
example.com/deviceA: 1
example.com/deviceB: 1
$ kubectl create -f test-deployment.yaml
deployment.apps/test-deployment created
-
The test-deployment pod should be scheduled on the worker-node-A node
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES device-plugin-a-ds-9bpsj 1/1 Running 0 3h13m 172.17.0.3 worker-node-B <none> <none> device-plugin-a-ds-dv55t 1/1 Running 0 3h13m 172.17.0.2 worker-node-A <none> <none> device-plugin-b-ds-8t7lh 1/1 Running 0 3h13m 172.17.0.2 worker-node-A <none> <none> device-plugin-b-ds-lt4pr 1/1 Running 0 3h13m 172.17.0.3 worker-node-B <none> <none> test-deployment-6dccf65ddb-pkg9j 1/1 Running 0 18s 172.17.0.2 worker-node-A <none> <none>