Lightweight coscheduling based on back-to-back queue sorting #
Table of Contents #
- Motivation
- Goals
- Non-Goals
- Use Cases
- Terms
- Proposal
- Design Details
- Known Limitations
- Alternatives considered
- Graduation Criteria
- Testing Plan
- Implementation History
- References
Motivation #
Kubernetes has become a popular solution for orchestrating containerized workloads. Due to limitation of Kubernetes scheduler, some offline workloads (ML/DL) are managed in a different system.. To improve cluster utilization and operation efficiency, we’d like to treat Kubernetes as a unified management platform. Given that ML jobs are All-or-Nothing: they require all tasks of a job to be scheduled at the same time. If the job only start part of tasks, it will wait for other tasks to be ready to begin to work. In the worst case, all jobs are pending leading to a deadlock. To solve this problem, co-scheduling is needed for the scheduler. This proposal tries to solve this problem by implementing a coscheduling plugin based on scheduler framework.
Goals #
- Use scheduler plugin, which is the most Kubernetes native way, to implement coscheduling.
- Lightweight implementation of coscheduling without the CRD of
PodGroup
Non-Goals #
Use CRD PodGroup - this design proposes a lightweight approach that doesn’t need to impose CRD management.
Use Cases #
When running a Tensorflow/MPI job, all tasks must start before they can do any work. This becomes a bigger problem when several jobs are competing to get all their tasks started. In worst case, all jobs are pending because of a deadlock: every job only start part of tasks, and waits for the other tasks to start. In worst case, all jobs are pending leading to a deadlock.
Terms #
- pgPod: pod belongs to some
PodGroup. - regularPod: a regular
Pod(which doesn’t havePodGroupNameset).
Proposal #
In order to implement coscheduling, we developed plugins in different extension points. In QueueSort we ensure that the Pods belonging to the same PodGroup are queued back-to-back. For example, suppose PodGroup A owns Pod-A1, Pod-A2, Pod-A3, while PodGroup B owns Pod-B1, Pod-B2. The pods of the two PodGroups should not interleave - it should be always <PodGroup-A, PodGroup-B> or the other way around; but never <Pod-A1, Pod-B1, Pod-A2, …>. In Permit phase we put the pod that doesn’t meet minAvailable into the WaitingMap and reserve resources until minAvailable are met or timeout is triggered. In Unreserve phase,clean up the pods that timed-out.
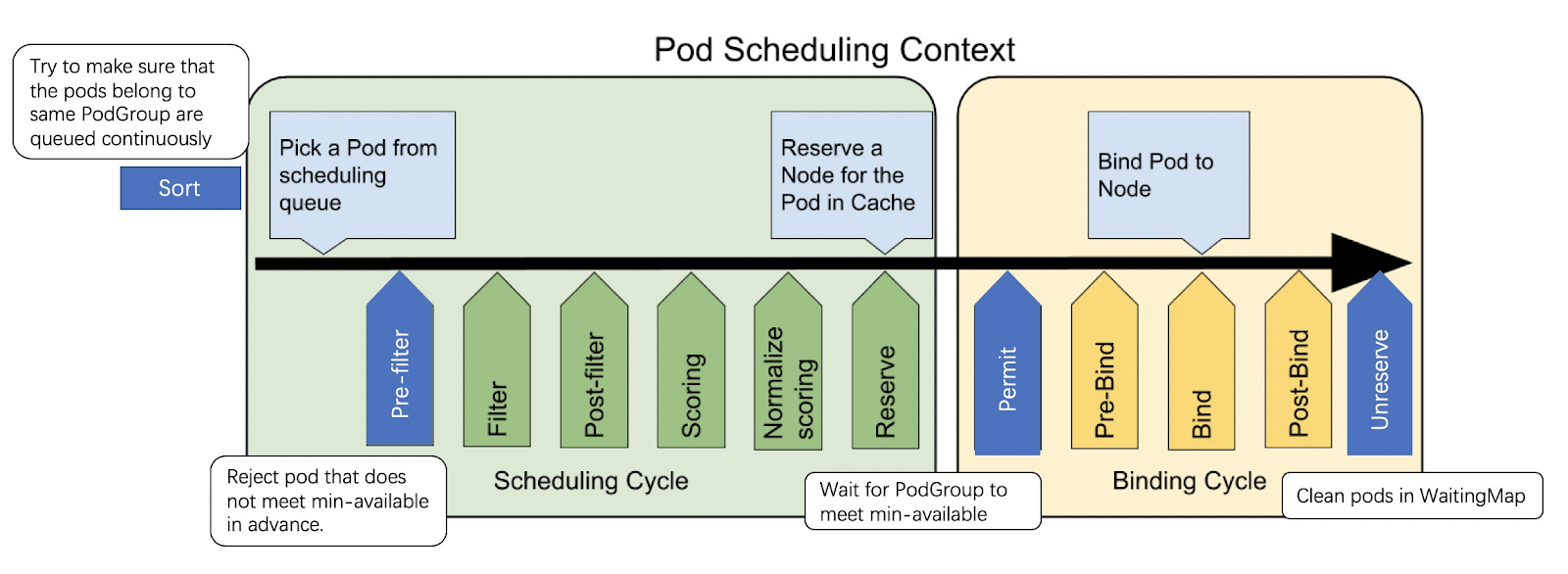
Design Details #
PodGroup #
We use a special label named pod-group.scheduling.x-k8s.io/name to define a PodGroup. Pods that set this label and use the same value belong to the same PodGroup. This is a short term solution, in the future if the definition of PodGroup is accepted by the community, we will define it directly through the CRD of PodGroup. This is not the focus of this proposal.
labels:
pod-group.scheduling.x-k8s.io/name: nginx
pod-group.scheduling.x-k8s.io/min-available: "2"
Pods in the same PodGroup with different priorities might lead to unintended behavior, so need to ensure Pods in the same PodGroup with the same priority.
Coscheduling #
// Coscheduling is a plugin that implements the mechanism of gang scheduling.
type Coscheduling struct {
FrameworkHandle framework.Handle
PodLister corelisters.PodLister
// Key is the name of PodGroup.
PodGroupInfos map[string]PodGroupInfo
}
type PodGroupInfo struct {
// InitialTimestamp stores the timestamp of the initialization time of PodGroup.
InitialTimestamp time.Time
UID types.UID
MinAvailable int
Name string
}
PodGroupInfois initialized the first time the pod belongs to the PodGroup is encountered,InitialTimestampstores the timestamp of the initialization time of PodGroup.UIDis the unique identification value used to distinguish different podgroups.
Extension points #
QueueSort #
In order to maximize the chance that the pods which belong to the same PodGroup to be scheduled consecutively, we need to implement a customized QueueSort plugin to sort the Pods properly.
func Less(podA *PodInfo, podB *PodInfo) bool
Firstly, we will inherit the default in-tree PrioritySort plugin so as to honor .spec.priority to ensure high-priority Pods are always sorted ahead of low-priority ones.
Secondly, if two Pods hold the same priority, the sorting precedence is described as below:
-
If they are both regularPods (without particular PodGroup label), compare their
InitialAttemptTimestampfield: the Pod with earlierInitialAttemptTimestampis positioned ahead of the other. -
If one is regularPod and the other is pgPod, compare regularPod’s
InitialAttemptTimestampwith pgPod’sInitialTimestamp: the Pod with earlier timestamp is positioned ahead of the other. -
If they are both pgPods:
- Compare their
InitialAttemptTimestamp: the Pod with earlier timestamp is positioned ahead of the other. - If their
InitialAttemptTimestampis identical, order by their UID of PodGroup: a Pod with lexicographically greater UID is scheduled ahead of the other Pod. (The purpose is to tease different PodGroups with the sameInitialAttemptTimestampapart, while also keeping Pods belonging to the same PodGroup back-to-back)
- Compare their
PreFilter #
When a pgPod is being scheduled for the first time, we have 2 option to deal with it: either start the full scheduling cycle no matter its grouping Pods are present inside schedule queue, or fail quick its scheduling cycle as its grouping Pods number doesn’t meet minAvailable. The former case is more efficient, but may cause partial Pods holding system resources until a timeout. The latter case may result in extra scheduling cycles (even if we’re going to fail them fast), but will reduce the overall scheduling time for the whole group - as we’re waiting them to be all present in the queue first and then start the full scheduling cycle for each).
Here we’re adopting the latter approach, PreFilter validates that if the total number of pods belonging to the same PodGroup is less than minAvailable. If so, the scheduling process will be interrupted directly.
Permit #
In Permit phase, we put the pod that doesn’t meet minAvailable into the WaitingMap and reserve resources until minAvailable are met or timeout is triggered.
- Get the number of Running pods that belong to the same PodGroup
- Get the number of WaitingPods (used to record pods in waiting status) that belong to the same PodGroup
- If Running + WaitingPods + 1 >=
minAvailable(1 means the pod itself), approve the waiting pods that belong to the same PodGroup. Otherwise, put the pod into WaitingPods and set the timeout (eg: the timeout is dynamic value depends on the size of thePodGroup.)
UnReserve #
After a pod which belongs to a PodGroup times out in the permit phase. UnReserve Rejects the pods that belong to the same PodGroup to avoid long-term invalid reservation of resources.
Known Limitations #
-
QueueSortis the core part of our design and only oneQueueSortplugin is allowed in the scheduling framework. So our design only supports the case thatQueueSortextension point isn’t implemented in other plugins. -
If the number is lower than min, our design moves pods to the “unschedulable” queue. But there is no way to bring them back unless some condition in the cluster changes that makes the pod “more schedulable”. At present, we rely on flush mechanism every one minute to solve this problem. In the future, we will take a proactive approach to bring them back when the number is equal or greater than min.
Alternatives considered #
- Using
PodGroupas a scheduling unit. This requires major refactoring, which only supports Pods as scheduling unit today.
Graduation Criteria #
Testing Plan #
- Add detailed unit and integration tests for workloads.
- Add basic e2e tests, to ensure all components are working together.